How To Use Regular Expressions in Search/Replace
Runestone supports searching for regular expressions and replacing capture matching capture groups in those expressions. Enable searching for regular expressions by selecting the ellipsis and selecting Regular Expression.
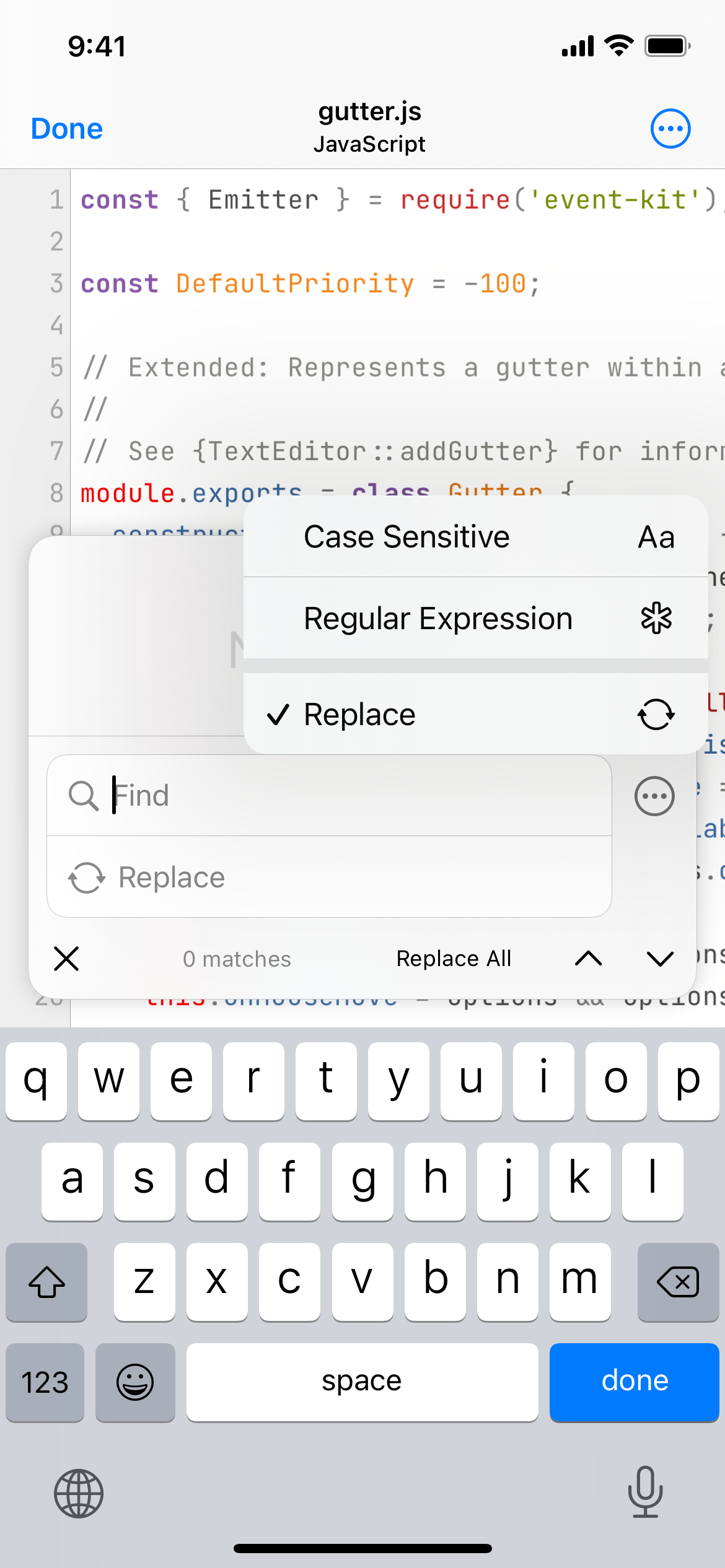
Input in the Find text field will now be treated as a regular expression.
Runestone's regular expressions are implemented using Apple's NSRegularExpression and as such conforms to the ICU specification for regular expressions.
Covering how to write regular expressions is out of scope for this article but there are plenty of resources on that on the Internet. Below are links to some of those resources.
- Learn regex the easy way by Zeeshan Ahm.
- Regular Expressions Cheat Sheet by Dave Child.
- regular expressions 101 by Firas Dib.
- NSRegularExpression by Apple.
When using capture groups, that is (...), in the query, you can refer to the contents of those capture groups using $1 for the first capture group, $2 for the second group, and so forth. $0 refer to the contents of the entire match.
Runestone's replacement expression supports the following modifiers for changing the casing of a capture group.
| Modifier | Behavior |
|---|---|
| \u | Uppercase the first letter in the capture group. |
| \U | Uppercase all letters in the capture group. |
| \l | Lowercase the first letter in the capture group. |
| \L | Lowercase all letters in the capture group. |
The screenshot below shows how a regular expression query, capture groups, and modifiers can be used to find all strings (denoted by '...') that contain a dash, remove the first dash, and uppercase the first letter in the word after the dash.
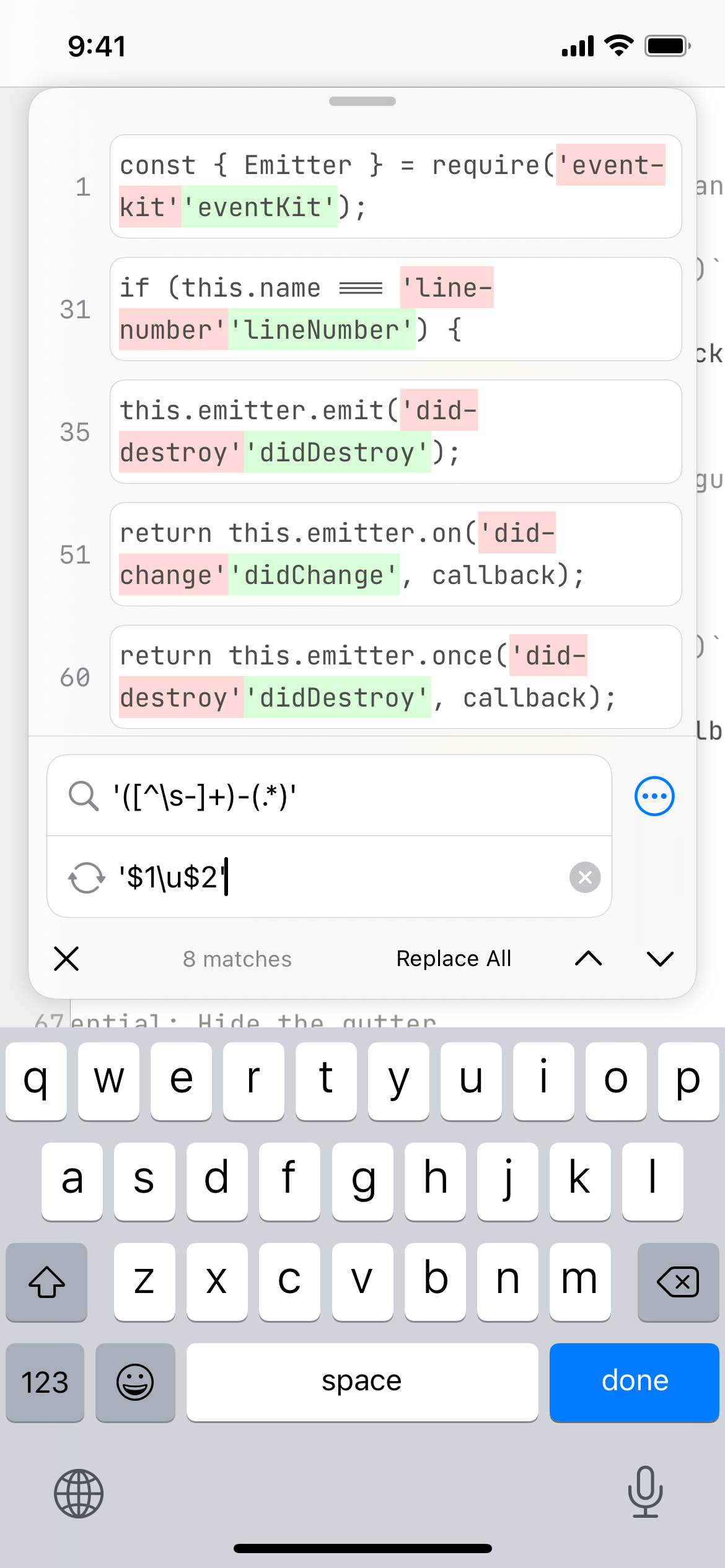
We use the following query to find strings that contain at least one dash and have separate capture groups for the text before the first dash and the text after the first dash: '([^\s-]+)-(.*)'. The table below breaks down the regular expression.
| Character | Meaning |
|---|---|
| ' | No special meaning in this case. Denotes the beginning of a string. |
| ( | Open a capture group. |
| [ | Open a range of characters. |
| ^ | When following the opening of a range it means that we do not want to match characters that are in the range. In this case, we are not matching whitespace and dash. |
| \s | Whitespace. We are not interested in strings that contain whitespace. We are not matching dashes as we want to end this capture group when we find whitespace. |
| - | No special meaning in this case. We are not matching dashes as we want to end this capture group when we find a dash. |
| ] | Close a range of characters. |
| + | One or more occurrences. In this case, we are looking for one or more occurrence of characters that are not whitespace or the dash. |
| ) | Close a capture group. |
| - | No special meaning in this case. Used to signify that we are only interested in strings that contain a dash. |
| ( | Open a capture group. |
| . | Match any character. |
| * | Zero or more occurrences. We are looking for zero or more of any characters. |
| ) | Close a capture group. |
| ' | No special meaning in this case. Denotes the end of a string. |
The above query will match strings like event-kit, line-number, did-change-visibility but not did change visibility since it does not contain any dashes.
In order to replace the first letter in the word following the dash we use this query: '$1\u$2'. The table below breaks down the query.
| Character | Meaning |
|---|---|
| ' | No special meaning in this case. Denotes the beginning of a string. |
| $1 | Refer to the contents of the first capture group. For example, in the string event-kit that would be event. |
| \u | Uppercase the first letter in the contents of the following capture. |
| $2 | Refer to the contents of the second capture group. For example, in the string event-kit that would be kit. |
| ' | No special meaning in this case. Denotes the end of a string. |